Publications |
|
Filter by:
|
|
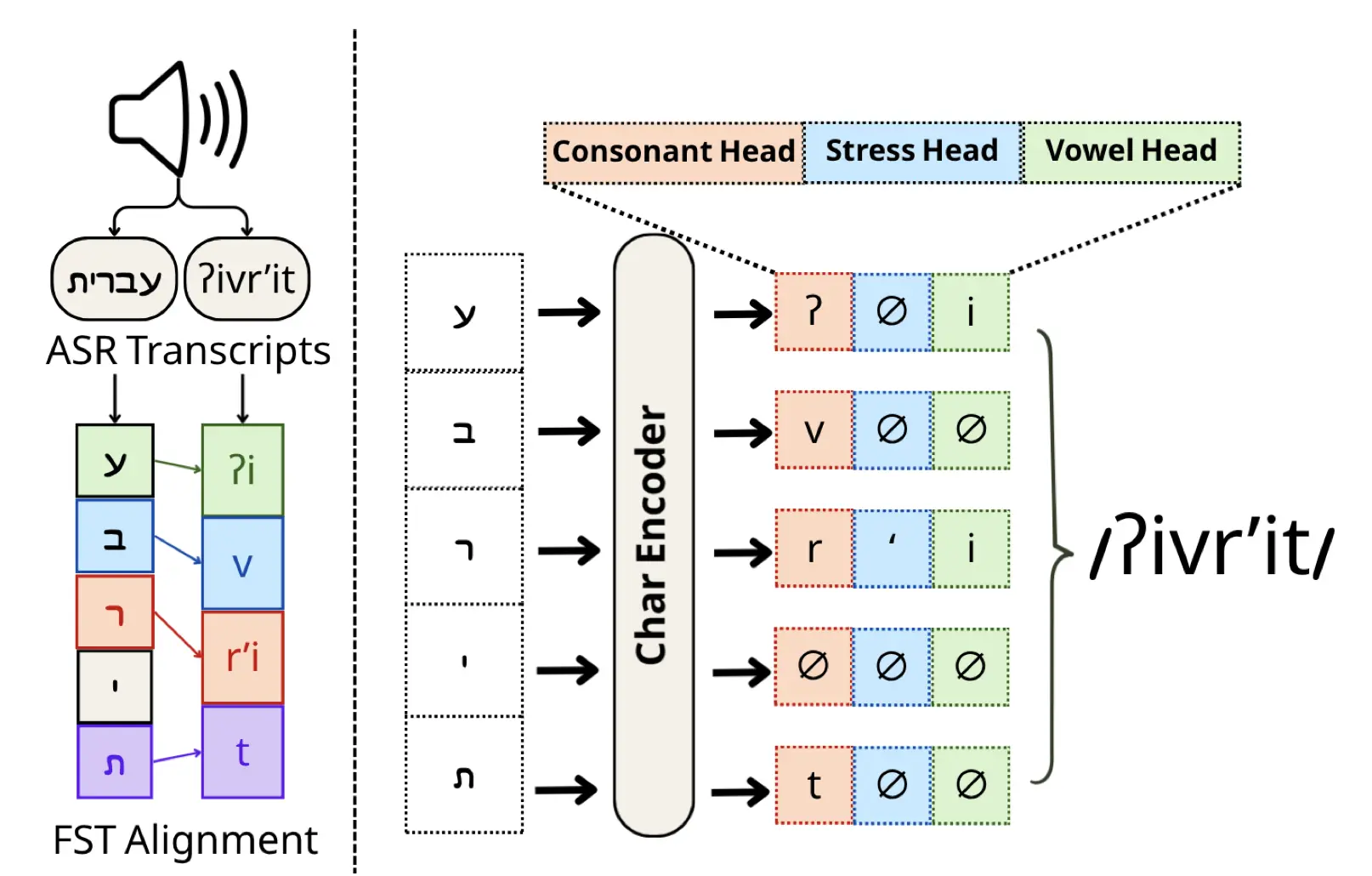
ReNikud: Audio-Supervised Hebrew Grapheme-to-Phoneme Conversion
Maxim Melichov*, Yakov Kolani*, Morris Alper arXiv, 2026 Audio/SpeechLow-Resource Languages ReNikud improves Hebrew grapheme-to-phoneme conversion by leveraging weak audio supervision from unlabeled speech and a pseudo-vocalization architecture with character-level alignment as an inductive bias. |

|
NAMESAKES: Probing Identity Memorization in Text-to-Image Models
Morris Alper, Vasudha Varadarajan, Moran Yanuka, Angelina Wang, Hadar Averbuch-Elor arXiv, 2026 Vision-LanguageInterpretability NAMESAKES is a benchmark of over 1,000 public figures with a black-box behavioral probe for detecting whether text-to-image models memorize and reproduce individuals' likenesses, requiring no reference photos or model internals. |
|
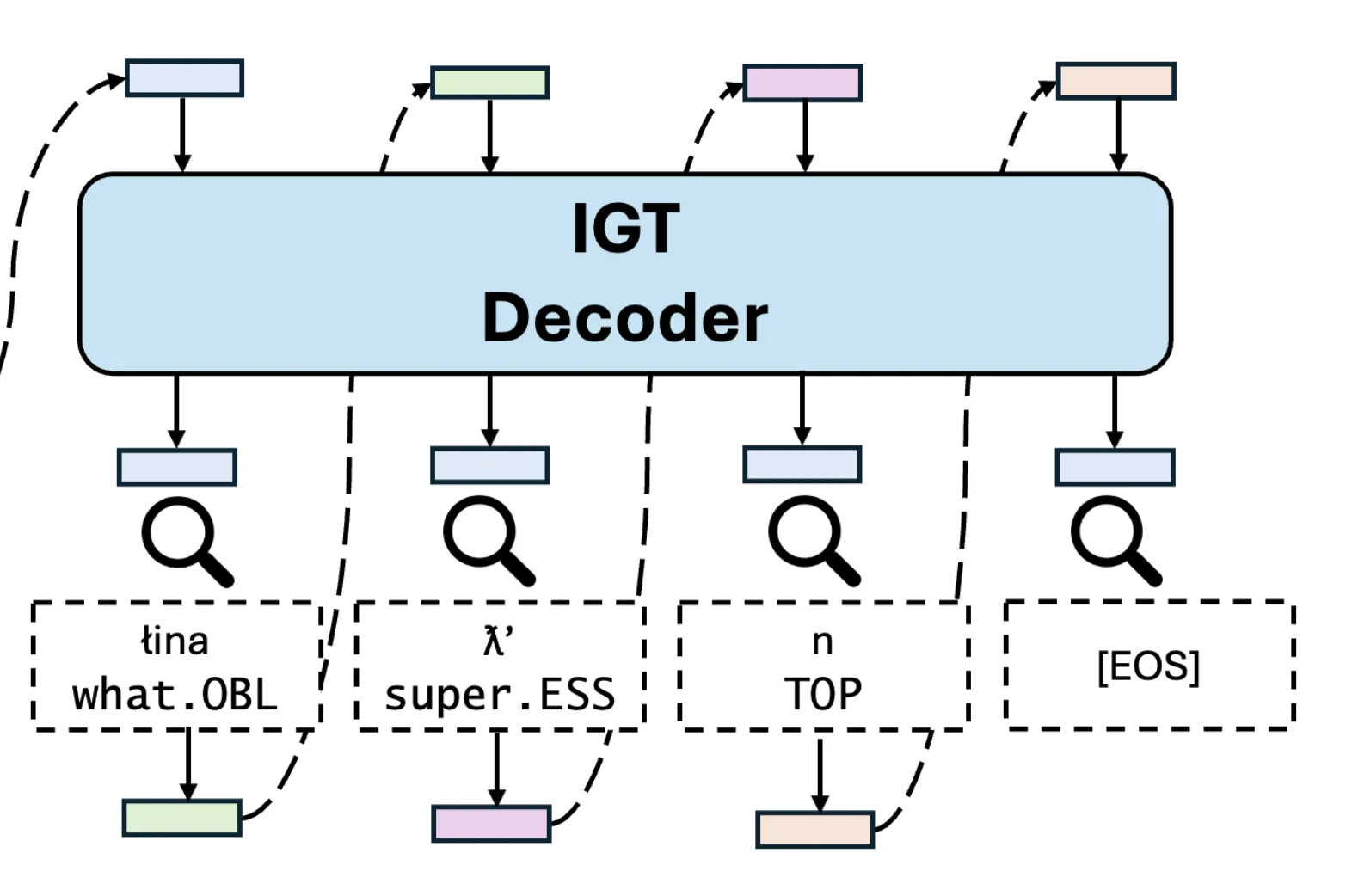
CWoMP: Morpheme Representation Learning for Interlinear Glossing
Morris Alper*, Enora Rice*, Bhargav Shandilya*, Alexis Palmer, Lori Levin *Equal contribution arXiv, 2026 Digital HumanitiesLow-Resource Languages CWoMP (Contrastive Word-Morpheme Pretraining) treats morphemes as atomic units, contrastively learning morpheme representations to automate interlinear glossed text (IGT) production for language documentation. |
|
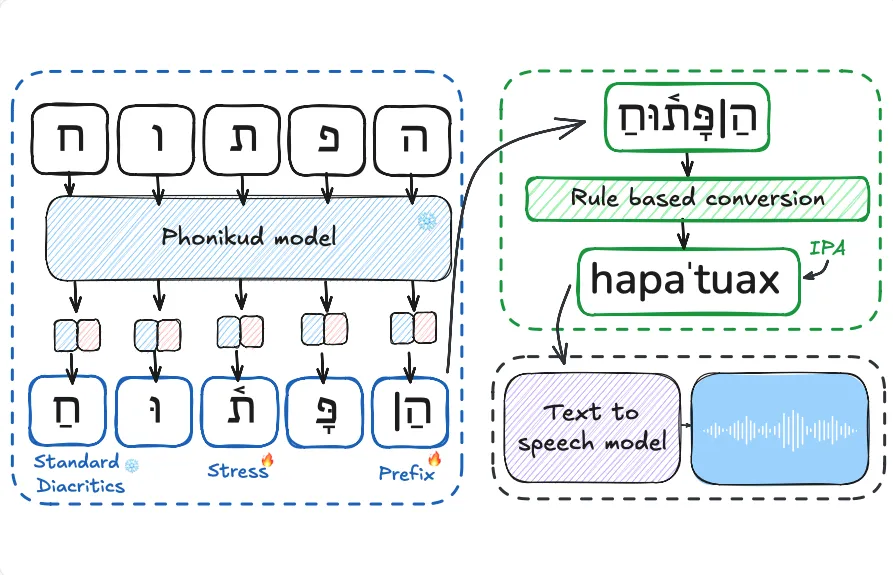
Phonikud: Overcoming Phonetic Underspecification for Hebrew Text-To-Speech
Yakov Kolani, Maxim Melichov, Cobi Calev, Morris Alper Interspeech, 2026 Audio/SpeechLow-Resource Languages Phonikud is an open-source Hebrew grapheme-to-phoneme system outputting fully-specified IPA transcriptions including stress. We also introduce ILSpeech, a Hebrew audio-text-IPA corpus, a G2P benchmark, and audio-to-IPA models for TTS evaluation. |
|
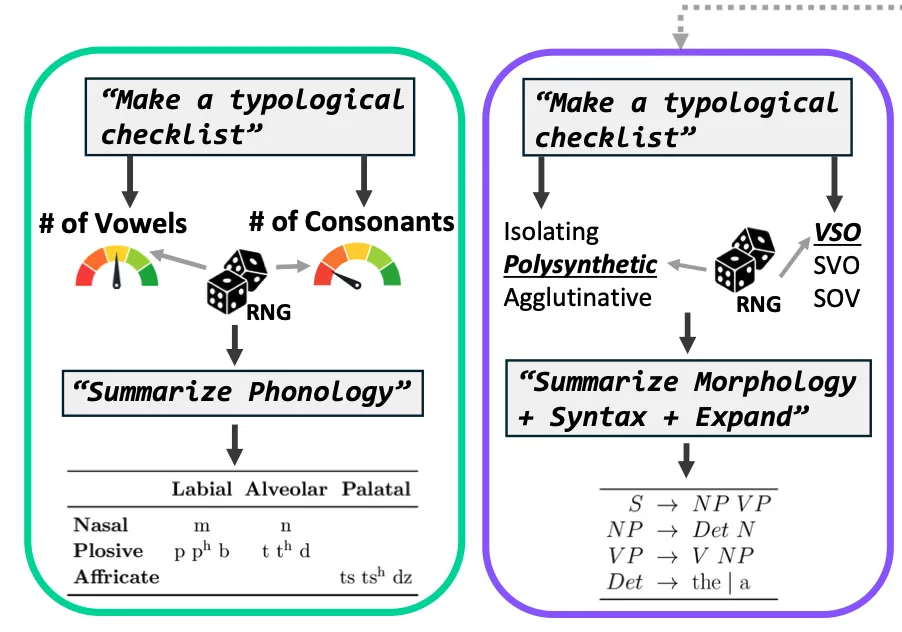
ConlangCrafter: Constructing Languages with a Multi-Hop LLM Pipeline
Morris Alper*, Moran Yanuka*, Raja Giryes, Gašper Beguš *Equal contribution ACL (Oral), 2026 Low-Resource Languages ConlangCrafter leverages LLMs to generate constructed languages through a multi-hop pipeline that decomposes language design into modular stages, with components encouraging consistency and typological diversity. |

|
WildCAT3D: Appearance-Aware Multi-View Diffusion in the Wild
Morris Alper, David Novotny, Filippos Kokkinos, Hadar Averbuch-Elor, Tom Monnier NeurIPS, 2025 Computer Vision WildCAT3D generates novel views of scenes learned from diverse 2D scene image data captured in the wild, enabling appearance-controlled novel view synthesis from a single image. |
|
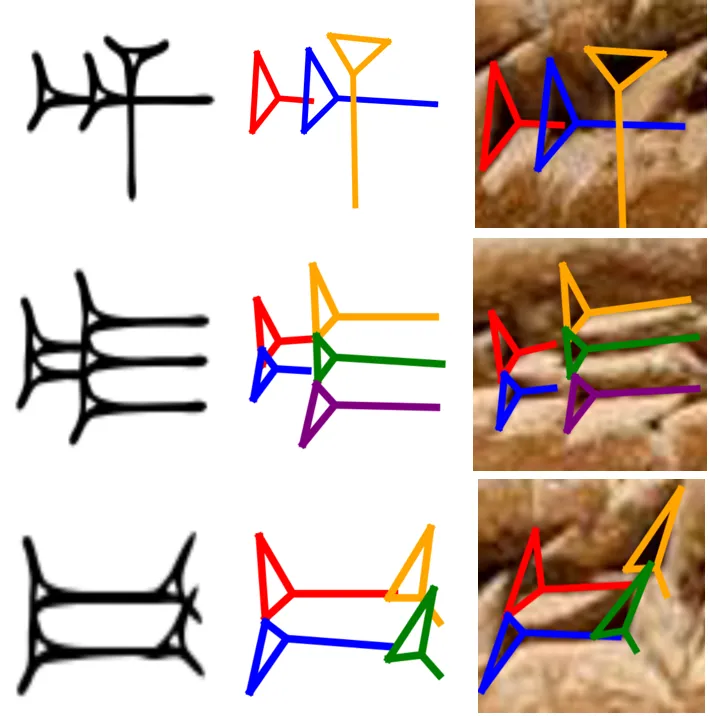
ProtoSnap: Prototype Alignment for Cuneiform Signs
Rachel Mikulinsky*, Morris Alper*, Shai Gordin, Enrique Jimenez, Yoram Cohen, Hadar Averbuch-Elor *Equal contribution ICLR, 2025 Digital HumanitiesComputer Vision ProtoSnap aligns prototype-based skeletons to cuneiform sign scans, with applications for downstream cuneiform OCR. |
|
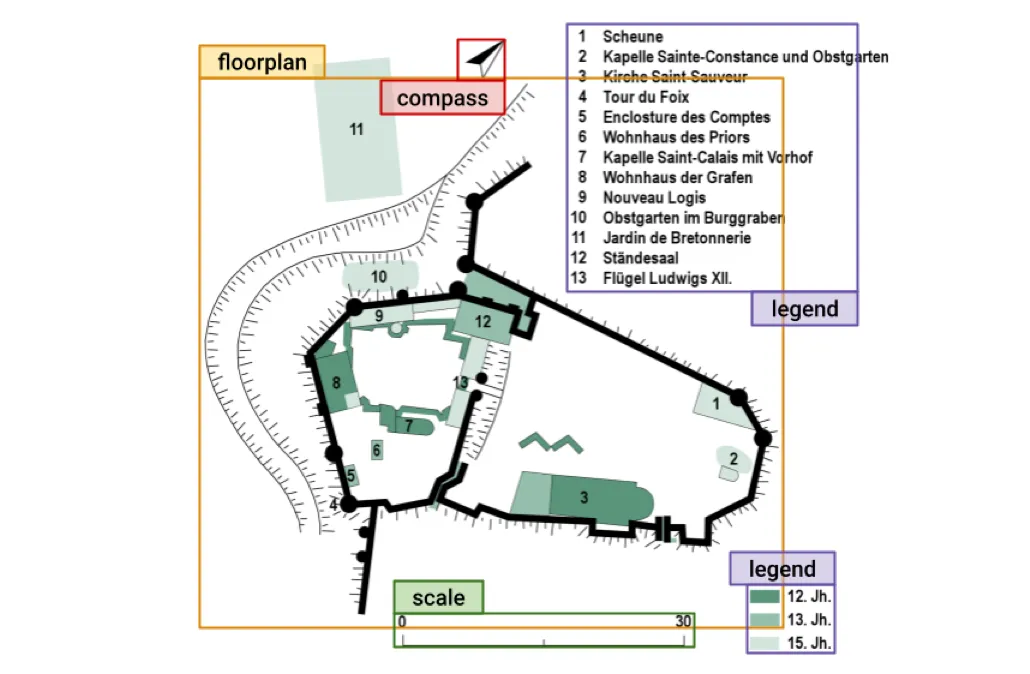
WAFFLE: Multimodal Floorplan Understanding in the Wild
Keren Ganon*, Morris Alper*, Rachel Mikulinsky, Hadar Averbuch-Elor *Equal contribution WACV (Oral), 2025 Computer Vision WAFFLE is a multimodal floorplan understanding dataset of nearly 20K diverse floorplan images and metadata, enabling progress on new building understanding tasks. |
|
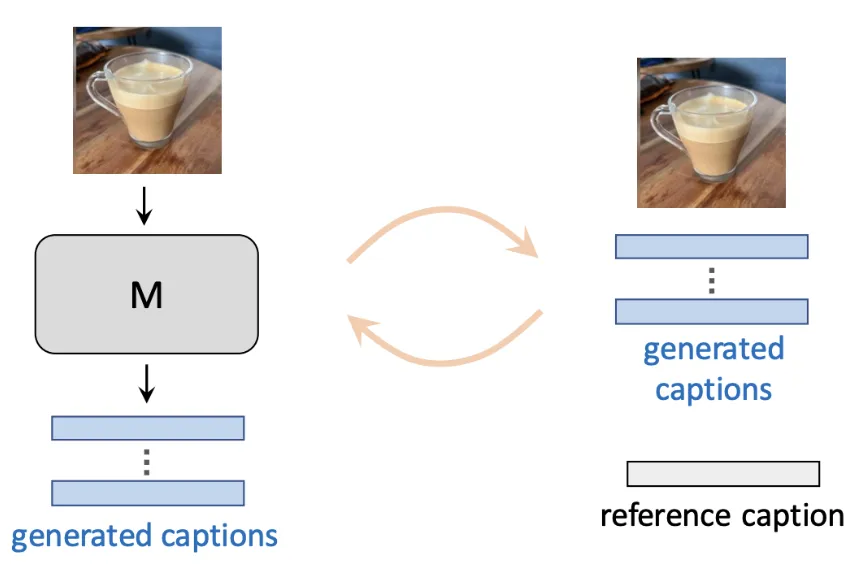
Mitigating Open-Vocabulary Caption Hallucinations
Assaf Ben-Kish, Moran Yanuka, Morris Alper, Raja Giryes, Hadar Averbuch-Elor EMNLP, 2024 Vision-Language A framework for addressing open-vocabulary hallucinations in image captioning models, including a new benchmark and a reinforcement learning-based method to reduce such hallucinations. |
|
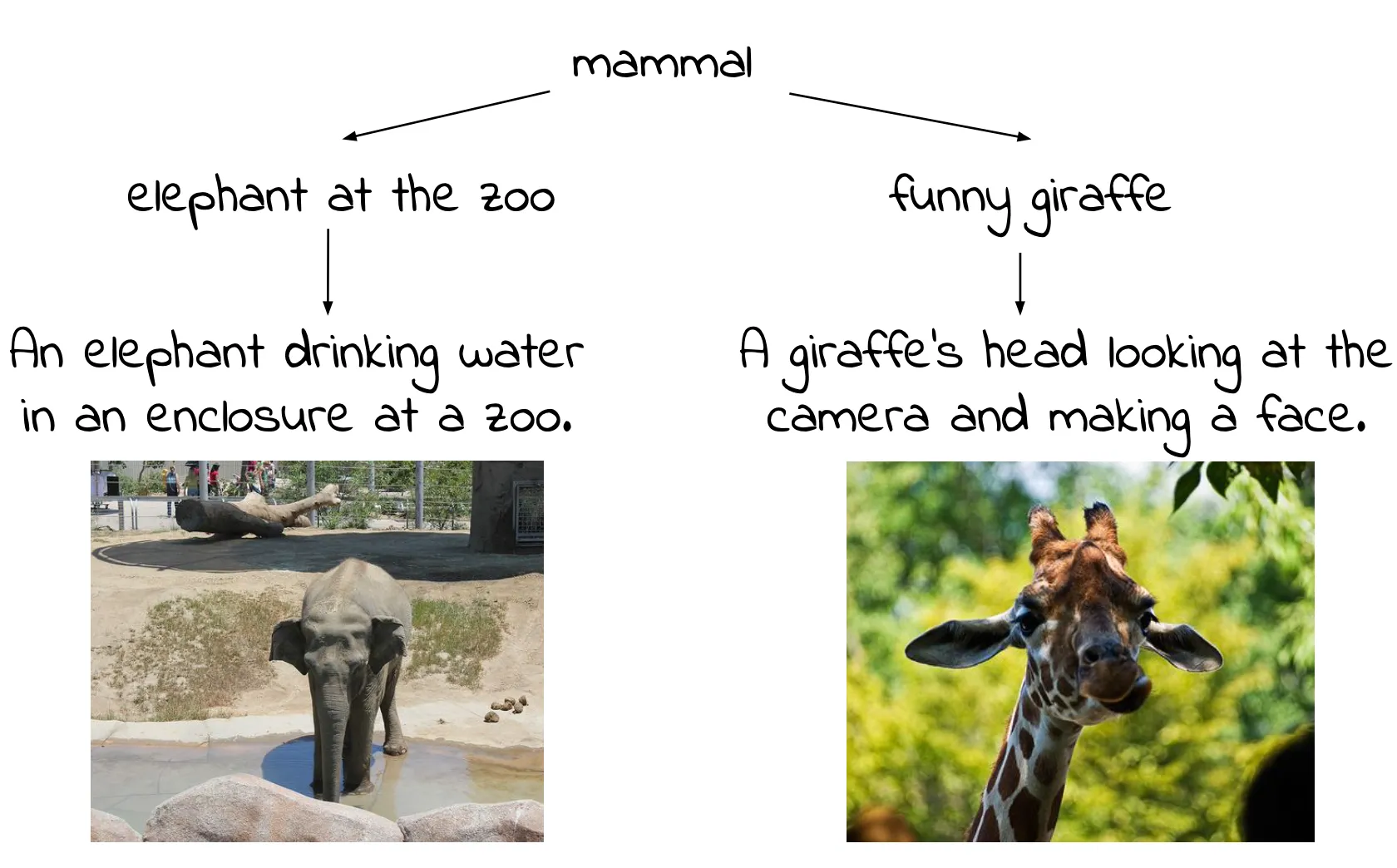
Emergent Visual-Semantic Hierarchies in Image-Text Representations
Morris Alper, Hadar Averbuch-Elor ECCV (Oral), 2024 Vision-LanguageInterpretability We show that foundation VLMs like CLIP model visual-semantic hierarchies, proposing the Radial Embedding framework for probing and optimizing this knowledge, along with the HierarCaps dataset of ground-truth image caption hierarchies. |

|
ICC : Quantifying Image Caption Concreteness for Multimodal Dataset Curation
Moran Yanuka, Morris Alper, Hadar Averbuch-Elor, Raja Giryes ACL (Findings), 2024 Vision-Language We quantify image caption concreteness using information loss in foundation vision-language models, and use this score to filter web-scale multimodal datasets. |

|
HaLo-NeRF:
Learning Geometry-Guided Semantics for Exploring Unconstrained Photo Collections
Chen Dudai*, Morris Alper*, Hana Bezalel, Rana Hanocka, Itai Lang, Hadar Averbuch-Elor *Equal contribution Eurographics, 2024 Computer VisionVision-Language We learn a semantic localization field for textual descriptions over collections of in-the-wild images depicting a large-scale scene. |

|
Kiki or Bouba? Sound Symbolism in Vision-and-Language Models
Morris Alper, Hadar Averbuch-Elor NeurIPS (Spotlight), 2023 Presentation from IMVC 2024 Vision-LanguageInterpretability By generating images using prompts containing pseudowords (nonsense words) and analyzing their shapes, we show that AI image generation models show sound-shape associations similar to those known from human psychology. |

|
Learning Human-Human Interactions in Images from Weak Textual Supervision
Morris Alper, Hadar Averbuch-Elor ICCV, 2023 Vision-Language We model human-human interaction understanding in images as free text generation, provide a new benchmark and show how to learn this with weak supervision from Internet image captions. |

|
Is BERT Blind? Exploring the Effect of Vision-and-Language Pretraining on Visual Language
Understanding
Morris Alper*, Michael Fiman*, Hadar Averbuch-Elor *Equal contribution CVPR, 2023 Vision-LanguageInterpretability We find that multimodally trained text encoders outperform unimodally trained text encoders on visual reasoning in text. |